Introducing forever.fm
I’m very proud to announce the launch of my latest project – forever.fm, an automatic, infinite online DJ. Forever.fm is a beatmatched stream of the hottest tracks from SoundCloud, mixed together to sound awesome, and continuing forever. (No advertisements, DJ chatter, or breaks!) Check it out!

WARNING: Past this point, you’ll find only gory technical details of how forever.fm was made.
Overview
Forever is powered by a large number of technologies, some of which I stole from my previous music hack, the Wub Machine:
- For this project, I chose to use a 512MB Linode VPS, which has been running spectacularly.
- The entire site runs on Python and uses Facebook’s Tornado evented server.
- To stream track metadata, waveforms, and other live updates, I’ve used Socket.IO and tornadio2, its Tornado wrapper.
- the SoundCloud API provides the songs, metadata and audio streams that you hear.
- the Echo Nest Remix API analyzes each song to find the best beats for beatmatching.
- The Echo Nest released some cool beatmatching examples back in 2010, and my beatmatching code is heavily based off of their capsule example. (Although heavily patched to fix memory leaks, allow infinite execution and lighter CPU usage.)
- LAME and FFMPEG for efficient encoding and decoding of the MP3 stream.
- I found some great code for approximating the Travelling Salesman Problem by John Montgomery. This is used for ordering tracks – more on that later.
- Scott Schiller’s spectacular SoundManager2 JavaScript library and 360º player UI play back the audio stream in-browser and provide very neat visualizations.
- the Python Imaging Library is used to colour, stylize, and fade the waveforms of each song.
- Charles Leifer’s algorithm for using k-means to find the dominant colours in images is used to colour each track based on its album artwork.
Streaming MP3 in Python
The toughest problem to solve when creating Forever was that of live streaming. The core beatmatching algorithm at its heart (“Capsule”) has existed for a couple years now. However, making this run infinitely required some different approaches.
Python’s built-in generators provide a great way to implement an iterative beatmatching algorithm, as each generator can carry its own internal state. In this case, that state is the last-played song. Here’s some pseudocode:
def forever(track_queue):
t1 = track_queue.get()
while not track_queue.empty():
t2 = track_queue.get()
yield make_transition(t1, t2)
t1 = t2
This code is obviously oversimplified, but basically how the core of Forever works. Assuming that forever constantly yields raw audio data (i.e.: WAV, AIFF, PCM), this needs to be encoded to MP3 and streamed out to the user.
To tackle this MP3 problem, I created a LAME MP3 encoder interface in Python that allows real-time, buffered and synchronized MP3 encoding.
With this simple interface, Forever hands off chunks of large, raw audio data to LAME for MP3 encoding. Python then reads single MP3 frames from LAME as they become available and puts those frames into a queue. (If the queue is full, this blocks and prevents more raw audio from being generated, essentially throttling the entire process via negative queue pressure.)
Finally, someone has to read from this MP3 queue. After trying custom thread-based solutions for throttling this properly, I instead settled on a much more stable solution – asking the Tornado web server itself to hand out each MP3 frame as it becomes available. Surprisingly, this is extremely stable, and results in a perfectly real-time stream with no lead or lag:
SECONDS_PER_FRAME = 1152.0 / 44100 # As defined by the spec
seconds_to_buffer = 60
mp3_queue = Queue(int(seconds_to_buffer / SECONDS_PER_FRAME))
. . .
def send():
frame = mp3_queue.get_nowait()
if not frame:
print "OH NOES, MP3 queue is empty!"
return
for listener in listeners:
listener.send(frame)
. . .
PeriodicCallback(send, SECONDS_PER_FRAME * 1000).start()
This strategy has not (yet) been load tested, but is nevertheless the system I’m using in production at the moment. For all I know, this could fail completely while serving a large number of listeners. Testing locally by spinning up 200 instances of CURL, this performs admirably and causes Python to use only 5% of my aging Macbook’s CPU.
Interestingly, placing a limit on this final MP3 buffer propagates this queue pressure backwards all the way to the audio generator. If the output MP3 buffer is full, the LAME wrapper will be blocked until it can write to the queue. If LAME’s output is blocked, then an internal semaphore will block in the LAME wrapper’s input function, which will delay the audio generator. (Internally, the LAME wrapper writes all of the PCM to the LAME process at once, to prevent encoding delay and decrease memory usage by only storing lightweight MP3 instead of heavy PCM. This blocking behaviour is artifically implemented to save memory.)
Memory Leaks and Python C Extensions
In the process of implementing Forever using the Echo Nest’s action and cAction libraries, I ran across an absurdly annoying bug that took me into the depths of Python C extensions. Each time I executed a Crossfade.render or pydirac.timeStretch call, I lost memory. (A lot of memory – often between 25 and 100 MB.) As Forever is built around these methods, I couldn’t have used them as-is – but I couldn’t find a suitable replacement, as they were written specifically for this purpose by Tristan Jehan, a co-founder of the Echo Nest.
So I busted out Apple’s Instruments, which include a memory profiler. Upon initial search, I found no actual memory leaks. (i.e.: There were no calls to malloc without a corresponding free.) However, memory was increasing linearly over time on the smallest possible test case – something was definitely being leaked!
As Python is a garbage-collected language, I then turned to the internal heap in an attempt to find objects without references. After trying guppy and heapy to find the size of Python’s heap, I realized it wouldn’t help. PCM audio in the Echo Nest API is stored within numpy arrays – which are garbage collected, but whose memory is allocated outside of Python. Searching for numpy arrays with heapy, guppy, or the wonderful objgraph ends up being relatively futile, as the large chunks of memory that you’re searching for won’t be in the scope of Python.
This left one possibility – the C extensions being used were leaving a reference to the large Numpy array somewhere. As it turns out, this was the case. (Discovered by manually reading the code, finding every PyObject*, and tracing it to ensure that its reference count was handled properly.) The solution?
. . . .
215 + Py_DECREF(inSound1);
216 + Py_DECREF(inSound2);
215 217 return PyArray_Return(outSound);
. . . .
As it turns out, a Numpy array allocation function (NA_InputArray) was being used incorrectly. The docs state that the return value of this function should should always be DECREF’d, but they weren’t. It’s that simple, but with such a huge impact.
The Dreaded GIL
After fixing the memory leaks, optimizing the beatmaching algorithms and ensuring that the system runs indefinitely, I ran into another problem – Python’s global interpreter lock. As Wikipedia explains succintly, a GIL is:
a mutual exclusion lock held by a programming language interpreter thread to avoid sharing code that is not thread-safe with other threads. In languages with a GIL, there is always one GIL for each interpreter process. CPython and CRuby use GILs.
This poses a big problem for Forever. The Tornado server has to deal out MP3 frames in real time to each listener, so any execution delays will cause noticeable audio dropouts. Worse still, the important audio operations needed to beatmatch songs (including calls to the aforementioned C extensions) are very computiationally expensive, often holding the GIL for seconds at a time. (Note: there exists a simple way to release the GIL from extension code that I haven’t yet tried, which might mitigate the issue.)
To work around this and ensure total isolation between heavy, blocking audio operations and efficient, real-time MP3 streaming, Forever makes use of Python’s multiprocessing module to split itself into server and worker processes. By opening a queue (well, multiple queues) between the server and the worker, the server can consistently stream MP3 packets in real time, while the worker thread can block and hold the GIL for any amount of time.
In theory.
Unfortunately, the synchronized Queue class provided in the multiprocessing module buffers its data in the sending process, not the receiving process. This means that even if the Queue is full of audio, the GIL of the worker process could be acquired by one thread, preventing the server process from reading any data from the queue until it is released. This doesn’t help at all.
To work around this restriction yet again, I created a simple BufferedReadQueue class that eagerly fetches all of the data from the child process and simply buffers it in the parent, allowing the parent to read data even when the child’s GIL is blocked, and providing an isolated buffer of audio data to safeguard against dropouts.
Cycles of Similar Songs
A significant part of what makes Forever sound good is its choice of tracks. One of the hardest problems that a DJ faces is choosing which tracks to play in their set, and Forever is no different. To solve this problem programatically, I created a module called the Brain and turned to graph theory.
Forever starts by grabbing a list of the top n tracks from SoundCloud, ordered by “hotness.” It then culls this list by removing songs that are too short, too long, or duplicates of other songs in the list. Forever then arranges the remaining tracks in a complete graph, where each song is a vertex, and each edge describes a measure of “distance” between tracks – an inverse of similarity, if you will. For example, if two tracks have similar tempo, tags and genre, their similarity will be high, making the edge weight between them very low.
Here’s an example of the edge weights in a simple three-song graph:
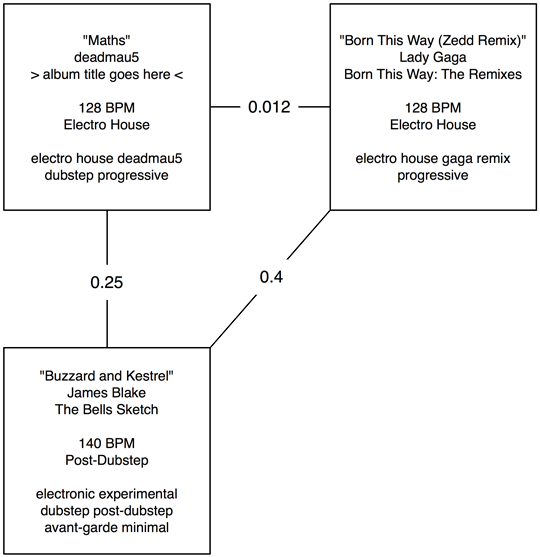
To play these songs forever, the problem reduces to finding the lowest-weight cycle in the entire undirected graph… which requires a solution to the Travelling Salesman Problem. As TSP is one of the great NP-complete problems in computer science, I resort to using approximation algorithms. Forever uses a great bit of Python code for a hill-climbing approximation, written by John Montgomery to “solve” this problem. After running the approximation for something like 10,000 iterations, I accept the solution and use that to order the resulting tracks.
After the track order is determined, the worker process receives these tracks and begins to remix them in order when necessary. At this step, the worker fetches the Echo Nest’s analysis (a very lengthy call) to find the metadata required to beatmatch each track. With this data comes a great “summary” that includes many factors that would be useful for determining track order – including energy, danceability and loudness. Hence, this summary data is cached in a SQLite database to allow the Brain to make better decisions.
Live Brain Transplants (Reloading Modules)
Once Forever was working without dropouts or stalls, I faced another issue. If I wanted to make a code change to any of the core algorithms, I’d usually just restart the server. However, if there are people listening to the radio stream, this would cut them off, as the underlying socket connection to the server would be broken as soon as the Python server process is killed. Hence, to ensure a truly endless stream of audio, I had to find a way to hot-swap portions of code that I might want to update frequently.
To test this, I started with Forever’s Brain module. To wrap the Brain in a container that could easily hot-swap its internal logic, I created another module – aptly-named “skull.” This module performs the infinite loop around the Brain’s logic, calling the Brain as a generator and adding its results directly to a limited queue. In short:
class Skull(threading.Thread):
def __init__(self, track_queue):
self.track_queue = track_queue
import brain
self.brain = brain
self.loaded = self.modtime
threading.Thread.__init__(self)
self.daemon = True
@property
def modtime(self):
return os.path.getmtime(self.brain.__file__)
def run(self):
g = self.brain.add_tracks()
while True:
if self.modtime != self.loaded:
log.info("Hot-swapping brain!")
self.brain = reload(self.brain)
self.loaded = self.modtime
g = self.brain.add_tracks()
track = g.next()
log.info("Adding new track to queue.")
self.track_queue.put(track)
I’ve since extended this concept to a number of other core modules – namely, the beatmatching generator, as I’m currently trying to increase its efficiency every day, and the MP3 decoding/encoding classes, as they’re still a bit too memory-hungry for my liking.
Conclusions
Try out Forever.fm. If you like the kind of music that’s popular on SoundCloud (currently lots of EDM) then you’ll enjoy it. I have big plans for it from here on out, but it was super fun to build, and I learned a ton. As always, feel free to email me or tweet at me if you have any questions.